
Text & Image (multimodal) streaming chat with Gemini AI on iOS with SwiftUI
Watch the video or follow along with the post below.
Previously, we saw how to easily integrate the Gemini Swift SDK to perform simple text-only interactions & then followed it up with creating a multi-turn chat interface with Gemini AI’s gemini-pro model.
In this post we will see how to perform multimodal (text-and-image) conversations using the gemini-pro & gemini-pro-vision models.
Before we begin, you must note that unlike the previous multi-turn chat interface which made use of the Chat object, we will be managing the chat history ourselves since gemini-pro-vision does not support multi-turn conversations yet.
From the documentation:
Note: The gemini-pro-vision model (for text-and-image input) is not yet optimized for multi-turn conversations. Make sure to use gemini-pro and text-only input for chat use cases.
Just as in the previous post, we create regular structs to form our chat message, with the inclusion of a property to hold image data.
enum ChatRole {
case user
case model
}
struct ChatMessage: Identifiable, Equatable {
let id = UUID().uuidString
var role: ChatRole
var message: String
var images: [Data]?
}
Then at the time of making the actual request to the AI SDK, we switch between the gemini-pro & gemini-pro-vision models depending on whether the prompt is accompanied with some image data or not.
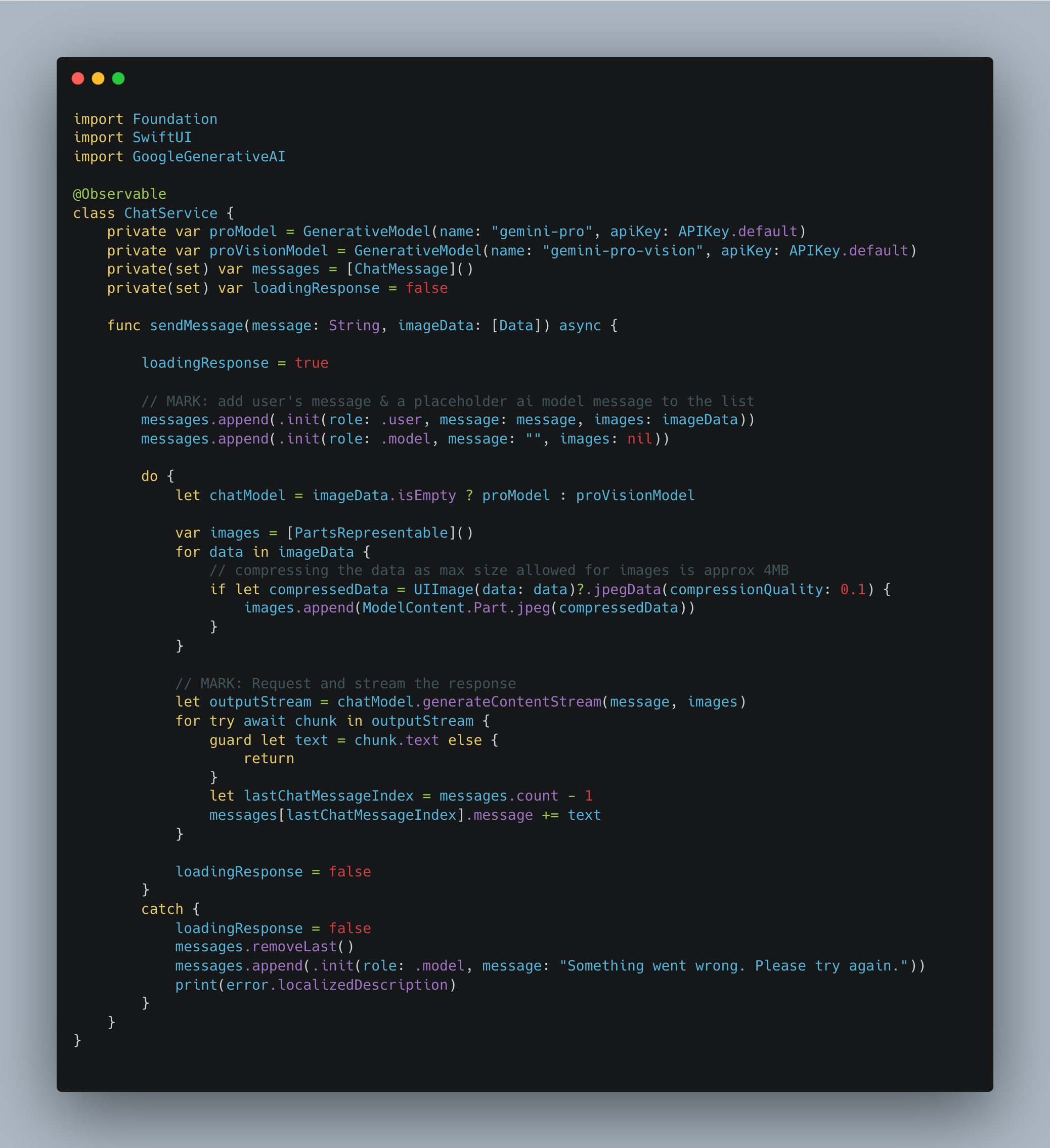
class ChatService {
var proModel = GenerativeModel(name: "gemini-pro", apiKey: APIKey.default)
var proVisionModel = GenerativeModel(name: "gemini-pro-vision", apiKey: APIKey.default)
let chatModel = imageData.isEmpty ? proModel : proVisionModel
}
We then convert the imageData if available into a PartsRepresentable form that is consumed by the API like so:
var images = [PartsRepresentable]()
for data in imageData {
// compressing the data as max size allowed for images is approx 4MB
if let compressedData = UIImage(data: data)?.jpegData(compressionQuality: 0.1) {
images.append(ModelContent.Part.jpeg(compressedData))
}
}
It seems that there is a size limitation for the images that can be passed & in my experiments it’s around 4MB which is why I’m compressing the image data above.
Finally we make a request to the SDK but this time calling generateContentStream() which allows us to build the response and display it in the UI as is being received instead of waiting for the complete response to be generated. This provides better interactions as depending on the prompt, response generation can take some time.
let outputStream = chatModel.generateContentStream(message, images)
for try await chunk in outputStream {
guard let text = chunk.text else {
return
}
let lastChatMessageIndex = messages.count - 1
messages[lastChatMessageIndex].message += text
}
The complete code looks like this
Reusing the chat interface code from the previous post along with some updates to allow users to pick photos(limited to 3 for this example) with the photo picker, we finally get this:
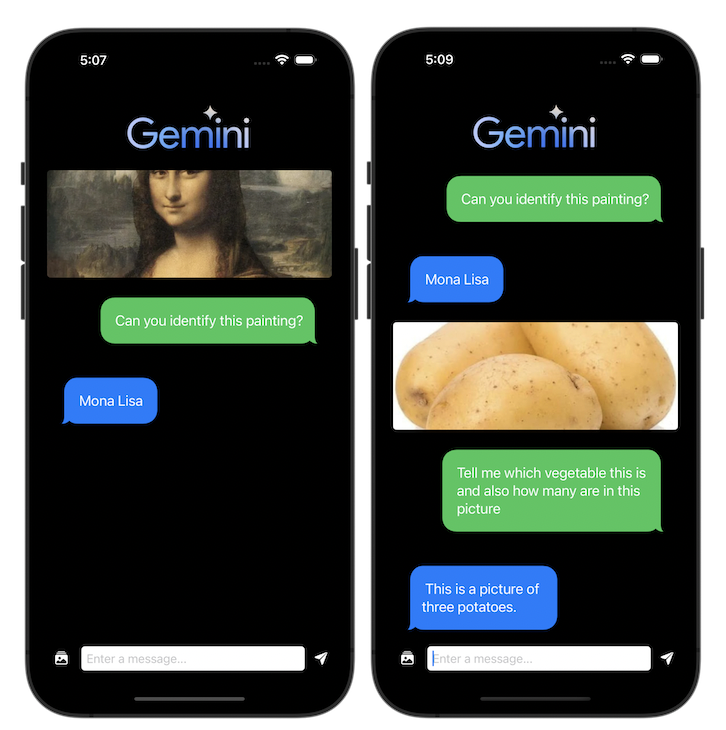
And that’s it! The complete code can be found here.
Leave a comment if you have any questions and share this article if you found it useful !